Section 01 Introduction and R
tutorial
Background Poll
1. Have you taken any statistics course before?
2. Do you use the following languages for data analysis?
MATLAB
Python
RIDL- Other
- No, I don’t
3. What do you use for data visualization?
MATLAB
Python
RIDLOrigin- Other (but not Excel or similar spreadsheet software)
- I use Excel, sometimes Power-point
4. On a scale of 0 (not any) to 10 (sophisticated), how to describe your programming experience?
5. What is your laptop’s operating system (OS)?
- Windows
- macOS
- Ubuntu
- Other
6. Name one thing you want to achieve at the end of the semester (open question)
Statistical topics to be covered
- Review of statistic basics
- Probability density function, distributions, statistical hypothesis, random draw, confidence interval, p-value
- Characteristics of environmental data sets
- Types of environmental data sets, format of environmental data sets, normal distribution, log normal distribution, log transformation, detection limit, missing values
- Checking data sets: Quick summaries
- Mean, median, quantile, standard deviation, variance, outlier
- Mean, median, quantile, standard deviation, variance, outlier
- Checking data sets: Quick plots
- Histogram, barplot, boxplot, scatterplot, time series plot, image plot, surface maps
- Comparisons between two groups
- t distribution, assumptions of t-test, comparing means of two groups, rank-Sum test, permutation test, Welch t-test, sign test, signed-rank test
- Comparisons among several groups
- One-way ANOVA, F-test, two-way ANOVA, linear combinations of group means, multiple comparison procedures
- Correlation tests
- Pearson’s test, Spearman’s test, Kendall’s test
- Simple linear regression
- Least squares regression estimation, robustness of least squares inferences, model assessment, fit assessment
- Multiple linear regression
- Least squares estimates, model assessment, fit assessment
- Over-fitting and variable selection
- Over-fitting, AIC, BIC, backward selection, forward selection, step-wise selection
- Logistic regression
- Binary responses, binomial responses, Poisson responses, building logistic regression model
- Time series analysis
- MA and AR model, SARIMA model fitting and prediction
- Cluster analysis
- Hierarchical clustering, K-Means clustering
Take the course or not?
This course is designed for ESE undergraduates having no or weak data
analysis background, with emphasis on R.
Good reasons for not taking the course:
- After browsing the syllabus and schedule, there is nothing new for me
- I am able to analyze, and visualize data sets through programming efforts already
- I want to learn other programming languages (
C,C++,Java,MATLAB,Python,IDL, etc.) - I want to take an “easy” class to meet the graduation requirement
Bad reasons for not taking the course:
- Data analysis is intimidating; perhaps I can never learn it
- I don’t have coding/programming experience
- My project does not require programming efforts
The R language
R is the leading tool for statistics, data analysis, and
machine learning. It is more than a statistical package; it’s a
programming language, so you can create your own
objects, functions, and packages.
Academics and statisticians have developed R over two
decades. R now has one of the richest ecosystems to perform
data analysis. There are around 16000 packages
available in CRAN (Comprehensive R
Archive Network). It is possible to find a library for
whatever the analysis you want to perform. The rich
variety of libraries makes R the first choice for
statistical and data analysis. R also makes communicating
the findings with a presentation, document, or website very easy.
The following figure summaries important reasons for learning
R:
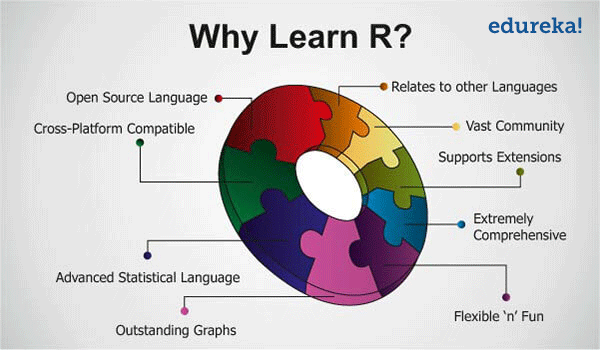
{kind=link}
First look at RStudio
Follow instructions to install RStudio.
The RStudio IDE (Integrated Development Environment) is the most
popular integrated development environment for R. It allows
you to write, run, and debug your R code.
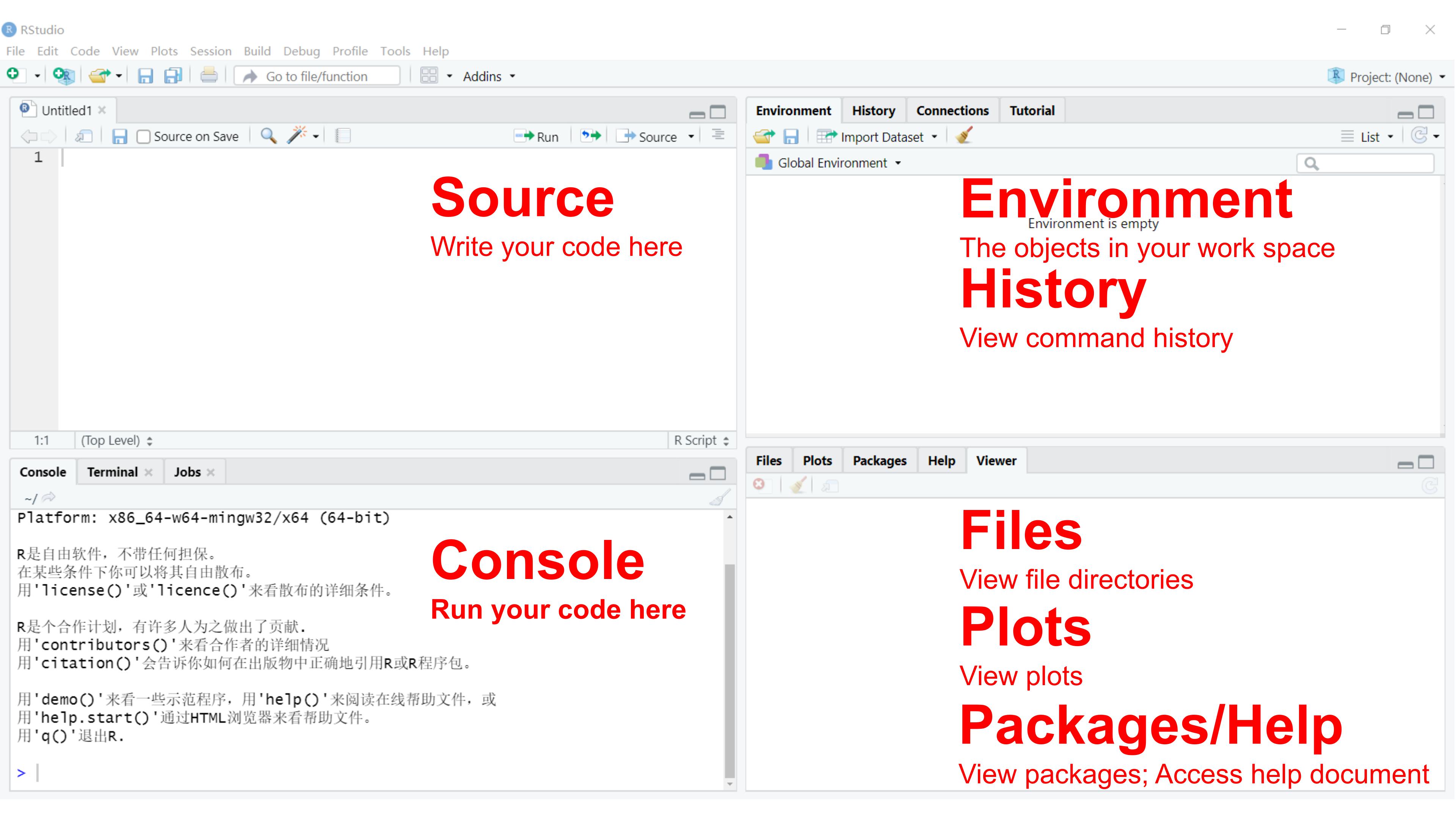
Check this cheat sheet (may need VPN) for more features and shortcuts of the RStudio IDE.
The notes below are modified from the excellent online R tutorial freely available on the Software Carpentry website.
Quick R tutorial
Using R as a calculator
The simplest thing you could do with R is to do
arithmetic. Let try this in the Console window:
## [1] 3R will print out the answer with a preceding
## [1] (my PC) or [1] (your laptop). Don’t
worry about this for now, we will explain that later. For now, think of
it as indicating output.
You will find the spaces have no impact on the result.
## [1] 3When using R as a calculator, the order of operations is
the same as you would have learned back in school. From highest to
lowest precedence:
- Parentheses:
(,) - Exponents:
^or** - Multiply:
* - Divide:
/ - Add:
+ - Subtract:
-
Let’s try
## [1] 7## [1] 9## [1] 27Always think about clarifying your intentions, as others may later
read your code. Here we call such intentions as comments.
Anything that follows after the hash symbol # is ignored by
R when it executes code.
## [1] 10Really small or large numbers get a scientific notation:
## [1] 2e-04You can write numbers in scientific notation too:
## [1] 5e+10## [1] 5320000Mathematical functions
R has many built-in mathematical functions. To call a
function, we can type its name, followed by open and closing parentheses
(). Anything we type inside the parentheses is called the
function’s arguments:
## [1] 0.841471## [1] 1## [1] 2.302585## [1] 1## [1] 1.648721Don’t worry about trying to remember every function in
R. You can look them up online, or if you can remember the
start of the function’s name, use the Tab completion in
RStudio.
This is one advantage that RStudio has over R on its
own; it has auto-completion abilities that allow you to more
easily look up functions, their arguments, and the values that they
take. In fact, the auto-completion abilities do not limit to functions,
but also to variables.
Typing a ? before the name of a command will open the
help page for that command. When using RStudio, this will open the
Help window. The help page will include a detailed
description of the command and how it works. Scrolling to the bottom of
the help page will usually show a collection of code examples that
illustrate command usage. We will go back to how to get help later in
this section.
Comparing things
We can also do comparisons in R:
## [1] TRUE## [1] TRUE## [1] TRUE## [1] TRUE## [1] TRUE## [1] TRUEA word of warning about comparing numbers: you should never use
== to compare two numbers unless they are integers (a data
type which can specifically represent only whole numbers).
Variables and assignment
We can store values in variables using the assignment operator
<-, like this:
Notice that the assignment does not print a value. Instead, we stored
it for later in something called a variable. x now
contains the value 0.01:
## [1] 0.01Remember, you can always print a variable (in fact, anything) using
the function print():
## [1] 0.01## [1] "Hello World"You can also assign a character to a variable
## [1] "SUSTech"Look for the Environment window from the top right
panel of RStudio, and you will see that x and its value
have appeared. Our variable x can be used in place of a
number in any calculation that expects a number:
## [1] -2Notice also that variables can be reassigned:
x used to contain the value 0.01, and now
it has the value 100.
Assignment values can contain the variable being assigned to:
The right-hand side of the assignment can be any valid R
expression. The right-hand side is fully evaluated
before the assignment occurs.
Variable names can contain letters, numbers, underscores, periods, but no spaces. They must start with a letter or a period followed by a letter (they cannot start with a number nor an underscore). Variables beginning with a period are hidden variables. Different people use different conventions for long variable names. Whatever you use is up to you, but be consistent.
Vectorization
One thing to be aware of is that R is
vectorized, meaning that variables and functions can have
vectors as values. In contrast to physics and mathematics, a vector in
R describes a set of values in a certain
order of the same data type. For example:
## [1] 1 2 3 4 5 6 7 8 9 10## [1] 2 4 8 16 32 64 128 256 512 1024## [1] 2 4 8 16 32 64 128 256 512 1024This is incredibly powerful; we will discuss this further in an upcoming section.
Managing your environment
There are a few useful commands you can use to interact with the
R session.
ls() will list all of the variables and functions stored
in the global environment (your working R session):
## [1] "ACF" "AQI" "AQI1" "AQI2" "average" "Baseline" "Beta0_hat" "Beta1_hat" "cd_data" "Cd_data" "cd_data_tbl"
## [12] "Check_Air_Quality" "co2" "co2_components" "Control" "Daily_T" "Day" "density" "density1" "density2" "density3" "density4"
## [23] "df" "df_B" "df_error" "df_regression" "df_W" "df1" "df2" "df3" "df4" "Diff" "difference"
## [34] "F_ratio" "Forecast_List" "full_model" "Groupings_A" "GZ_n" "GZ_PM2.5" "GZ_sigma" "Hour" "Hourly_T" "i" "k"
## [45] "Keeling_Data" "Keeling_Data_tbl" "lambda" "logistic" "M" "mean_A" "mean_B" "Month_CO2" "MSB" "MSE" "MSR"
## [56] "MSW" "MyName" "n" "N" "n1" "N1" "n2" "N2" "n3" "n4" "Obs_A"
## [67] "Obs_all" "Obs_B" "Obs_difference" "output" "Output_List" "Output_Matrix" "Output_Matrix2" "Ozone_data" "p_2.5th" "p_97.5th" "p_value"
## [78] "P_value" "P1" "P2" "P3" "PACF" "Pesticide_data" "Pesticide_data2" "PM" "PM_data" "PM2.5_2019" "PM2.5_2020"
## [89] "PM2.5_data" "Pop" "pop1" "pop2" "Pred_band" "Prediction" "r" "R2" "R2_adj" "Rainfall_data" "reg"
## [100] "res_aov" "residual" "s1" "s2" "Samle_size" "sample" "Sample" "Sample_mean" "sample1" "Sample1" "sample2"
## [111] "Sample2" "sample3" "sample4" "sample5" "sample6" "sd" "SD" "sd1" "sd2" "SE" "SE_beta1_hat"
## [122] "SE_W" "Seeded" "Simulations" "Soil_conc" "SSB" "SSE" "SSR" "SST" "SSW" "SZ_n" "SZ_PM2.5"
## [133] "SZ_sigma" "t" "t_beta1" "Temp_Value" "TOC" "Total_simulations" "Treat" "trModel" "two_way_additive" "two_way_interaction" "Unseeded"
## [144] "Uptaken_amount" "UV" "walsh.test" "x" "x1" "x2" "y" "y_new" "y1" "y2" "z"
## [155] "Z"Note here that we didn’t give any arguments to ls(), but
we still needed to give the parentheses () to tell
R to call the function.
You can use rm() to delete objects you no longer
need:
## [1] "ACF" "AQI" "AQI1" "AQI2" "average" "Baseline" "Beta0_hat" "Beta1_hat" "cd_data" "Cd_data" "cd_data_tbl"
## [12] "Check_Air_Quality" "co2" "co2_components" "Control" "Daily_T" "Day" "density" "density1" "density2" "density3" "density4"
## [23] "df" "df_B" "df_error" "df_regression" "df_W" "df1" "df2" "df3" "df4" "Diff" "difference"
## [34] "F_ratio" "Forecast_List" "full_model" "Groupings_A" "GZ_n" "GZ_PM2.5" "GZ_sigma" "Hour" "Hourly_T" "i" "k"
## [45] "Keeling_Data" "Keeling_Data_tbl" "lambda" "logistic" "M" "mean_A" "mean_B" "Month_CO2" "MSB" "MSE" "MSR"
## [56] "MSW" "MyName" "n" "N" "n1" "N1" "n2" "N2" "n3" "n4" "Obs_A"
## [67] "Obs_all" "Obs_B" "Obs_difference" "output" "Output_List" "Output_Matrix" "Output_Matrix2" "Ozone_data" "p_2.5th" "p_97.5th" "p_value"
## [78] "P_value" "P1" "P2" "P3" "PACF" "Pesticide_data" "Pesticide_data2" "PM" "PM_data" "PM2.5_2019" "PM2.5_2020"
## [89] "PM2.5_data" "Pop" "pop1" "pop2" "Pred_band" "Prediction" "r" "R2" "R2_adj" "Rainfall_data" "reg"
## [100] "res_aov" "residual" "s1" "s2" "Samle_size" "sample" "Sample" "Sample_mean" "sample1" "Sample1" "sample2"
## [111] "Sample2" "sample3" "sample4" "sample5" "sample6" "sd" "SD" "sd1" "sd2" "SE" "SE_beta1_hat"
## [122] "SE_W" "Seeded" "Simulations" "Soil_conc" "SSB" "SSE" "SSR" "SST" "SSW" "SZ_n" "SZ_PM2.5"
## [133] "SZ_sigma" "t" "t_beta1" "Temp_Value" "TOC" "Total_simulations" "Treat" "trModel" "two_way_additive" "two_way_interaction" "Unseeded"
## [144] "Uptaken_amount" "UV" "walsh.test" "x1" "x2" "y" "y_new" "y1" "y2" "z" "Z"## [1] "ACF" "AQI" "AQI1" "AQI2" "average" "Baseline" "Beta0_hat" "Beta1_hat" "cd_data" "Cd_data" "cd_data_tbl"
## [12] "Check_Air_Quality" "co2" "co2_components" "Control" "Daily_T" "Day" "density" "density1" "density2" "density3" "density4"
## [23] "df" "df_B" "df_error" "df_regression" "df_W" "df1" "df2" "df3" "df4" "Diff" "difference"
## [34] "F_ratio" "Forecast_List" "full_model" "Groupings_A" "GZ_n" "GZ_PM2.5" "GZ_sigma" "Hour" "Hourly_T" "i" "k"
## [45] "Keeling_Data" "Keeling_Data_tbl" "lambda" "logistic" "M" "mean_A" "mean_B" "Month_CO2" "MSB" "MSE" "MSR"
## [56] "MSW" "n" "N" "n1" "N1" "n2" "N2" "n3" "n4" "Obs_A" "Obs_all"
## [67] "Obs_B" "Obs_difference" "output" "Output_List" "Output_Matrix" "Output_Matrix2" "Ozone_data" "p_2.5th" "p_97.5th" "p_value" "P_value"
## [78] "P1" "P2" "P3" "PACF" "Pesticide_data" "Pesticide_data2" "PM" "PM_data" "PM2.5_2019" "PM2.5_2020" "PM2.5_data"
## [89] "Pop" "pop1" "pop2" "Pred_band" "Prediction" "r" "R2" "R2_adj" "Rainfall_data" "reg" "res_aov"
## [100] "residual" "s1" "s2" "Samle_size" "sample" "Sample" "Sample_mean" "sample1" "Sample1" "sample2" "Sample2"
## [111] "sample3" "sample4" "sample5" "sample6" "sd" "SD" "sd1" "sd2" "SE" "SE_beta1_hat" "SE_W"
## [122] "Seeded" "Simulations" "Soil_conc" "SSB" "SSE" "SSR" "SST" "SSW" "SZ_n" "SZ_PM2.5" "SZ_sigma"
## [133] "t" "t_beta1" "Temp_Value" "TOC" "Total_simulations" "Treat" "trModel" "two_way_additive" "two_way_interaction" "Unseeded" "Uptaken_amount"
## [144] "UV" "walsh.test" "x1" "x2" "y_new" "y1" "y2" "z" "Z"Conditional statements
Often when we are coding, we want to control the flow of our actions. This can be done by setting actions to occur only if a condition or a set of conditions are met. Alternatively, we can also set an action to occur a particular number of times.
There are several ways you can control flow in R. For
conditional statements, the most commonly used approaches are the
if and else constructs.
Given today’s AQI (Air Quality Index) value, suppose we want to write
a piece of code to check whether the Air Quality is excellent (AQI <=
50) or not.
Open a new R script
(File -> New File -> R Script), and you should see a
new panel in your RStudio. Type the following lines in the script, and
save it. Select the lines you want to run, there are two ways to do
so:
- Type
Ctrl+Enter - Click
RunthenRun Select Line(s)from the top-right of the Script window.
AQI <- 69
# If this condition is TRUE
if (AQI <= 50) {
# Do the following
print("Air Quality is Excellent")
}The print statement does not appear in the console
because AQI is larger than 50. To print a
different message for numbers larger than 50, we can add an
else statement.
# If this condition is TRUE
if (AQI <= 50) {
# Do the following
print("Air Quality is Excellent")
# If this condition is FALSE
} else {
print("Air Quality is NOT Excellent")
}## [1] "Air Quality is NOT Excellent"You can also test multiple conditions by using
else if.
if (AQI <= 50) {
print("Air Quality is Excellent")
} else if (AQI <= 100) {
print("Air Quality is GOOD")
} else {
print("Air Pollution!")
}## [1] "Air Quality is GOOD"Change AQI to 40, 80, and
120, check the ouput.
Important: when R evaluates the
condition inside if() statements, it is looking for a
logical element, i.e., TRUE or FALSE.
This can cause some headaches for beginners. For example:
## [1] "4 does not equal 3"We can use logical AND && and OR ||
operator for more than one condition:
## [1] "Air Quality is Good"Change AQI to 40, 80, and
120, check the ouput.
AQI1 <- 69
AQI2 <- 140
if (AQI1 <= 100 || AQI2 <= 100) {
print("There is at least 1 site with a GOOD air quality")
}## [1] "There is at least 1 site with a GOOD air quality"Change AQI1 to 40, 80, and
120, check the ouput.
Defining a Function
You probably have realized it’s really tedious to change the AQI variables. It would be really helpful to define a function that handles different inputs automatically.
A function is a set of statements organized together to perform a
specific task. R has a large number of in-built functions
and the user can create their own functions. In R, a
function is an object so the R interpreter is able to pass
control to the function, along with arguments that may be necessary for
the function to accomplish the actions. The function in turn performs
its task and returns control to the interpreter as well as any result
which may be stored in other objects.
An R function is created by using the keyword
function. The basic syntax of an R
function definition is as follows:
In the above AQI example, we can define a function named
Check_Air_Quality as:
Check_Air_Quality<- function(AQI) {
# Excellent
if (AQI <= 50) {
print("Air Quality is Excellent")
}
# Good
if (AQI > 50 && AQI <= 100) {
print("Air Quality is Good")
}
# Polluted, Level I
if (AQI > 100 && AQI <= 150) {
print("Air pollution, level I")
}
# Polluted, Level II
if (AQI > 150 && AQI <= 200) {
print("Air pollution, level II")
}
# Polluted, Level III
if (AQI > 200 && AQI <= 300) {
print("Air pollution, level III")
}
# Polluted, Level IV
if (AQI > 300) {
print("Air pollution, level IV")
}
}Call Check_Air_Quality with various AQI
values: 40, 80, 120,
160, 240, and 340:
## [1] "Air Quality is Excellent"## [1] "Air Quality is Good"## [1] "Air pollution, level I"## [1] "Air pollution, level II"## [1] "Air pollution, level III"## [1] "Air pollution, level IV"Repeating operations
If you want to iterate over a set of values, when the order of
iteration is important, and perform the same operation on each, a
for() loop will do the job. This is the most
flexible of looping operations, but therefore also the
hardest to use correctly.
In general, the advice of many R users would be to learn
about for() loops but to avoid using for()
loops unless the order of iteration is important: i.e., the
calculation at each iteration depends on the results of previous
iterations.
Let’s define a list Forecast_List, which contains daily
mean temperature forecasts in 5 days in Shenzhen:
Here c() means “combine”:
## [1] 28 27 28 26 27Now loop each element in Forecast_List:
for (Daily_T in Forecast_List) { # If this condition is TRUE
# Do following
print(Daily_T)
} # End of the for loop## [1] 28
## [1] 27
## [1] 28
## [1] 26
## [1] 27We can use a for() loop nested within another
for() loop to iterate over two things at once.
for (Daily_T in Forecast_List) {
for (Hour in 1:24) {
Hourly_T <- rnorm(1,Daily_T,5)
print(paste(Daily_T,Hourly_T))
}
}## [1] "28 25.3923604026012"
## [1] "28 31.1253313520996"
## [1] "28 29.3312645793713"
## [1] "28 27.0522579350741"
## [1] "28 28.3145119671856"
## [1] "28 32.4497622548807"
## [1] "28 20.2050756876285"
## [1] "28 26.6802289607538"
## [1] "28 29.2340489723988"
## [1] "28 27.195214170157"
## [1] "28 26.535611243398"
## [1] "28 30.1651037639263"
## [1] "28 32.8666034089468"
## [1] "28 26.5380765761435"
## [1] "28 28.5061920756603"
## [1] "28 24.698437368519"
## [1] "28 34.2317850409744"
## [1] "28 20.9723423247146"
## [1] "28 22.2427099438523"
## [1] "28 27.7401796804038"
## [1] "28 28.2371814498622"
## [1] "28 34.9827330996784"
## [1] "28 28.7840486453326"
## [1] "28 28.12196132572"
## [1] "27 25.8169196198037"
## [1] "27 25.6691386555191"
## [1] "27 32.7735959507539"
## [1] "27 34.3260868441884"
## [1] "27 21.3895669348724"
## [1] "27 27.1641352267513"
## [1] "27 35.9087036801782"
## [1] "27 27.6154203405889"
## [1] "27 31.7055521931901"
## [1] "27 26.1440222173576"
## [1] "27 36.9870992185675"
## [1] "27 29.0167283248798"
## [1] "27 31.9665511301269"
## [1] "27 21.2646390287863"
## [1] "27 27.7254968119305"
## [1] "27 26.0804023910386"
## [1] "27 33.9141783928506"
## [1] "27 27.7872836928968"
## [1] "27 24.5631767542372"
## [1] "27 35.9718926344437"
## [1] "27 26.5852469014516"
## [1] "27 32.6018196730543"
## [1] "27 29.541198763642"
## [1] "27 26.9501337770281"
## [1] "28 27.2855912205344"
## [1] "28 20.433920021305"
## [1] "28 31.4971082151829"
## [1] "28 23.3677546204732"
## [1] "28 25.6331134946633"
## [1] "28 15.1173762628347"
## [1] "28 34.7969980805116"
## [1] "28 25.1585587531003"
## [1] "28 29.7382297666331"
## [1] "28 31.1100609337299"
## [1] "28 27.3714736093738"
## [1] "28 27.9950301521101"
## [1] "28 32.6374973392045"
## [1] "28 38.7423722797087"
## [1] "28 22.8291709645722"
## [1] "28 31.4103971317602"
## [1] "28 38.2736581996386"
## [1] "28 33.1341924189037"
## [1] "28 26.6188347749753"
## [1] "28 35.8960574346862"
## [1] "28 20.330280290559"
## [1] "28 29.5771828947039"
## [1] "28 31.8758819330486"
## [1] "28 26.0457960302832"
## [1] "26 19.9742833481204"
## [1] "26 31.3903613801108"
## [1] "26 24.5028566982456"
## [1] "26 21.0974972841304"
## [1] "26 21.5717000103114"
## [1] "26 21.6297202706325"
## [1] "26 22.7107646685445"
## [1] "26 22.4969112527945"
## [1] "26 35.6633787786532"
## [1] "26 34.7602909511721"
## [1] "26 31.6765270601705"
## [1] "26 25.0915526917281"
## [1] "26 11.3107282910267"
## [1] "26 15.797911046601"
## [1] "26 33.0938645624625"
## [1] "26 25.7975560449485"
## [1] "26 17.3154943809169"
## [1] "26 22.1771459958806"
## [1] "26 20.9354309161738"
## [1] "26 23.0226650185837"
## [1] "26 31.8271932199695"
## [1] "26 23.2775697186863"
## [1] "26 22.3979167282004"
## [1] "26 17.2511565076787"
## [1] "27 31.1379440355363"
## [1] "27 28.8154851733944"
## [1] "27 33.5844450434628"
## [1] "27 33.1428478822018"
## [1] "27 25.1819623013342"
## [1] "27 29.4701141574522"
## [1] "27 26.1296082483632"
## [1] "27 36.5044615063666"
## [1] "27 33.7357212227633"
## [1] "27 22.0923894077085"
## [1] "27 32.2413814891112"
## [1] "27 22.7566803370071"
## [1] "27 12.6711778040711"
## [1] "27 19.9234707599341"
## [1] "27 27.4192148020149"
## [1] "27 27.6631129332498"
## [1] "27 31.0352097109269"
## [1] "27 21.8297507036949"
## [1] "27 23.1056378150869"
## [1] "27 31.6165875256623"
## [1] "27 30.6117085673382"
## [1] "27 28.683483933314"
## [1] "27 30.1944382180197"
## [1] "27 25.1810027651068"Here at each Hour we use the rnorm()
function to generate 1 random Gaussian sample with a mean
of Daily_T and a standard deviation of 5.
We notice in the output that when the first index
(Daily_T) is set to 28, the second index
(Hour) iterates through its full set of indices. Once the
indices of Hour have been iterated through, then
Daily_T moves to the next one (i.e.,
27). This process continues until the last index has been
used for each for() loop.
Rather than printing the results, we could write the loop output to a new object:
Output_List <- c()
for (Daily_T in Forecast_List) {
for (Hour in 1:24) {
Hourly_T <- rnorm(1,Daily_T,5)
Temp_Value <- paste(Daily_T,Hourly_T)
Output_List <- c(Output_List, Temp_Value)
}
}
print(Output_List)## [1] "28 31.7663765762794" "28 31.4026545928256" "28 30.3964818043304" "28 31.228416612843" "28 28.8447136125209" "28 23.8018006322846" "28 27.1838970973966" "28 22.7630490604675" "28 26.18644712993" "28 31.2153304168178" "28 24.6332557173412"
## [12] "28 25.3456240935234" "28 24.0777487611125" "28 41.853065570756" "28 23.5132877689762" "28 35.4980166933536" "28 20.6963620505864" "28 26.8152325169156" "28 25.296436085823" "28 33.2945747542131" "28 21.9971104335001" "28 32.1426607922838"
## [23] "28 25.829151028551" "28 29.4737948283706" "27 24.1040799465651" "27 36.2277802330608" "27 25.1397065764221" "27 24.710713067551" "27 23.6636332651498" "27 25.6406602047445" "27 18.2009914700977" "27 29.6575756893271" "27 14.2043027602895"
## [34] "27 32.3127612342523" "27 18.69201423132" "27 30.0274272779582" "27 21.8335092520999" "27 28.9015946373975" "27 27.0686788534657" "27 38.2416016882066" "27 38.5411595587887" "27 29.7121503038727" "27 28.9484201186488" "27 26.9884469793616"
## [45] "27 22.8353527975966" "27 41.990558840153" "27 23.67470539918" "27 26.4382103613397" "28 20.5675907526425" "28 28.9293147858836" "28 31.5432730229272" "28 30.2801471715027" "28 38.9249008056557" "28 28.148736462007" "28 28.0702116175543"
## [56] "28 26.4127655199898" "28 22.9168909752591" "28 28.0790963803728" "28 40.0390687360884" "28 29.271460020411" "28 30.2213733267115" "28 39.9150664592952" "28 27.5664685785384" "28 26.0442442265146" "28 33.0149017255134" "28 34.4999414152152"
## [67] "28 32.9380817062995" "28 30.6789980016019" "28 29.6267207534683" "28 25.6268273298281" "28 25.3261726156837" "28 30.1925151329138" "26 21.8034378227582" "26 15.1595629842644" "26 27.0275089005186" "26 22.498220949466" "26 24.7961135518282"
## [78] "26 23.4689521412558" "26 21.8633560714293" "26 25.663557136039" "26 20.6280870281896" "26 27.476898637903" "26 20.8819726650771" "26 20.0052525013497" "26 31.159530499192" "26 31.6840375679712" "26 29.7372486776816" "26 33.3796460404933"
## [89] "26 30.1674050800973" "26 26.6246371180577" "26 23.5196497462799" "26 18.7823895548787" "26 28.7325517751787" "26 32.1029350082997" "26 21.9311274173543" "26 20.0300064456935" "27 25.4600061643638" "27 19.7726757071118" "27 26.3239326929086"
## [100] "27 20.6846947552629" "27 21.3160273341359" "27 28.7792091513285" "27 23.4524702977284" "27 26.8179249174676" "27 23.2840096913234" "27 28.8832476738637" "27 29.7508805786263" "27 24.8231168746271" "27 33.0272923857934" "27 26.1662736891122"
## [111] "27 26.9490801788739" "27 21.8026654308739" "27 35.2500891888614" "27 27.9799683191602" "27 29.6136380542385" "27 24.2245220387589" "27 30.3801570280095" "27 32.4026435795729" "27 37.7856406731085" "27 19.3007619181571"This approach can be useful, but “growing your results” (building the result object incrementally) is computationally inefficient, so avoid it when you are iterating through a lot of values.
Important: One of the biggest things that trips up
novices and experienced R users alike, is building a
results object (vector, list, matrix,
data frame) as your for loop progresses. Computers are very bad
at handling this, so your calculations can very quickly slow to a crawl.
It’s much better to define an empty results object
beforehand of appropriate dimensions, rather than initializing an empty
object without dimensions. So if you know the end result will be stored
in a matrix-like above, create an empty matrix with 5 row
and 24 columns, then at each iteration stores the results
in the appropriate location.
Output_Matrix <- matrix(nrow=5, ncol=24)
for (Day in 1:5) {
Daily_T <- Forecast_List[Day]
for (Hour in 1:24) {
Hourly_T <- rnorm(1,Daily_T,5)
Temp_Value <- paste(Daily_T,Hourly_T)
Output_Matrix[Day, Hour] <- Temp_Value
}
}
Output_Matrix2 <- as.vector(Output_Matrix)
Output_Matrix2## [1] "28 24.523673861094" "27 39.458146043041" "28 21.9704561444868" "26 19.6860954786766" "27 30.3797816679415" "28 27.7068444751424" "27 27.1423193915553" "28 30.8733370218511" "26 25.0958750164547" "27 25.0491407024078" "28 30.1162205909803"
## [12] "27 24.7714472012815" "28 29.259069364301" "26 25.2708956469947" "27 29.0057571731595" "28 29.9402620336976" "27 29.6937546751017" "28 25.2193478466398" "26 25.9587960474676" "27 23.9522292902213" "28 27.2952104763103" "27 28.6390216753009"
## [23] "28 28.1087322043759" "26 24.8185243529461" "27 22.5725272756754" "28 30.808972441982" "27 27.604915146985" "28 34.1908855473634" "26 31.4505475143116" "27 30.8491287655608" "28 16.336994027824" "27 22.0398444191602" "28 25.0188127937533"
## [34] "26 26.1019713958027" "27 34.0542100030384" "28 27.8738833418576" "27 38.2108442737928" "28 30.9554158807049" "26 24.6413728720474" "27 30.9178994593168" "28 22.1089280043296" "27 21.6635433294051" "28 33.6540863328073" "26 29.5819310604553"
## [45] "27 33.2787235619491" "28 19.8878777377818" "27 33.4517597401161" "28 17.7961306468172" "26 28.2580823946335" "27 25.2280818943314" "28 19.8759500549293" "27 31.1967917250235" "28 22.0416943955118" "26 25.4623981065353" "27 31.1032439707553"
## [56] "28 30.1801557361652" "27 23.7076955953459" "28 27.4887250622438" "26 28.8203659407169" "27 25.8142382355109" "28 26.9544285236743" "27 28.0106053254684" "28 27.813541049431" "26 33.6467297808911" "27 24.3210791841114" "28 28.6313181721851"
## [67] "27 32.6248254876377" "28 31.250264651202" "26 23.0781074855682" "27 22.9258560114055" "28 23.9352072544611" "27 30.402146328196" "28 34.4930972159246" "26 25.1875578611606" "27 27.8352574058838" "28 22.4027763108789" "27 36.5533192271719"
## [78] "28 34.7252658850172" "26 23.6042058131915" "27 31.1509702485124" "28 25.0810536662028" "27 24.6837577010038" "28 33.8600297302956" "26 35.882966186756" "27 27.3403548037912" "28 22.9280057223382" "27 26.739886304294" "28 23.1765150107041"
## [89] "26 27.161517533977" "27 24.6495971388073" "28 21.8440276648601" "27 28.7482312999999" "28 22.8952058998691" "26 30.6880495947209" "27 24.8638702999762" "28 28.9936324663399" "27 18.4184061780996" "28 31.4865144002634" "26 24.9234520814318"
## [100] "27 23.9724696797455" "28 29.6078478699275" "27 29.4526551807042" "28 13.1611893648623" "26 17.648653650712" "27 19.2965976200495" "28 37.9845054157656" "27 24.175038318465" "28 24.2722021461822" "26 17.8620494429826" "27 17.1315593756921"
## [111] "28 29.6306637980488" "27 22.6167910896604" "28 27.0243477485108" "26 29.5898781889537" "27 29.8652332938187" "28 25.9215571062706" "27 22.2533181563983" "28 31.4973418604527" "26 30.8034721282848" "27 35.2495804621542"Here we use matrix() to create an empty matrix with
5 rows and 24 columns, and use
as.vector() to convert the 5x24 matrix into a
vector with a length of 120.
Sometimes you will find yourself needing to repeat an operation as
long as a certain condition is met. You can do this with a
while() loop.
z <- 0
while(z <= 5){ # While this condition is TRUE
# Do following
z <- z + 1
print(z)
} # End of the while loop## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5
## [1] 6OK, can you figure out why the number 6 is also
printed?
while() loops will not always be
appropriate. You have to be particularly careful that
you don’t end up stuck in an infinite loop because your condition is
always met, and hence the while statement never terminates.
R Packages
It is possible to add functions to R by writing a
package or by obtaining a package written by someone else. As
of this writing, there are over 16000 packages available on
CRAN (the comprehensive R archive network). RStudio has functionality
for managing packages. You can:
- See what packages are installed by typing
installed.packages() - Install packages by typing
install.packages("packagename"), wherepackagenameis the package name, in quotes. - Update installed packages by typing
update.packages() - Remove a package with
remove.packages("packagename") - Make a package available for use with
library(packagename), no quotes.
Packages can also be viewed, loaded, and detached in the Packages tab of the lower-right panel in RStudio.
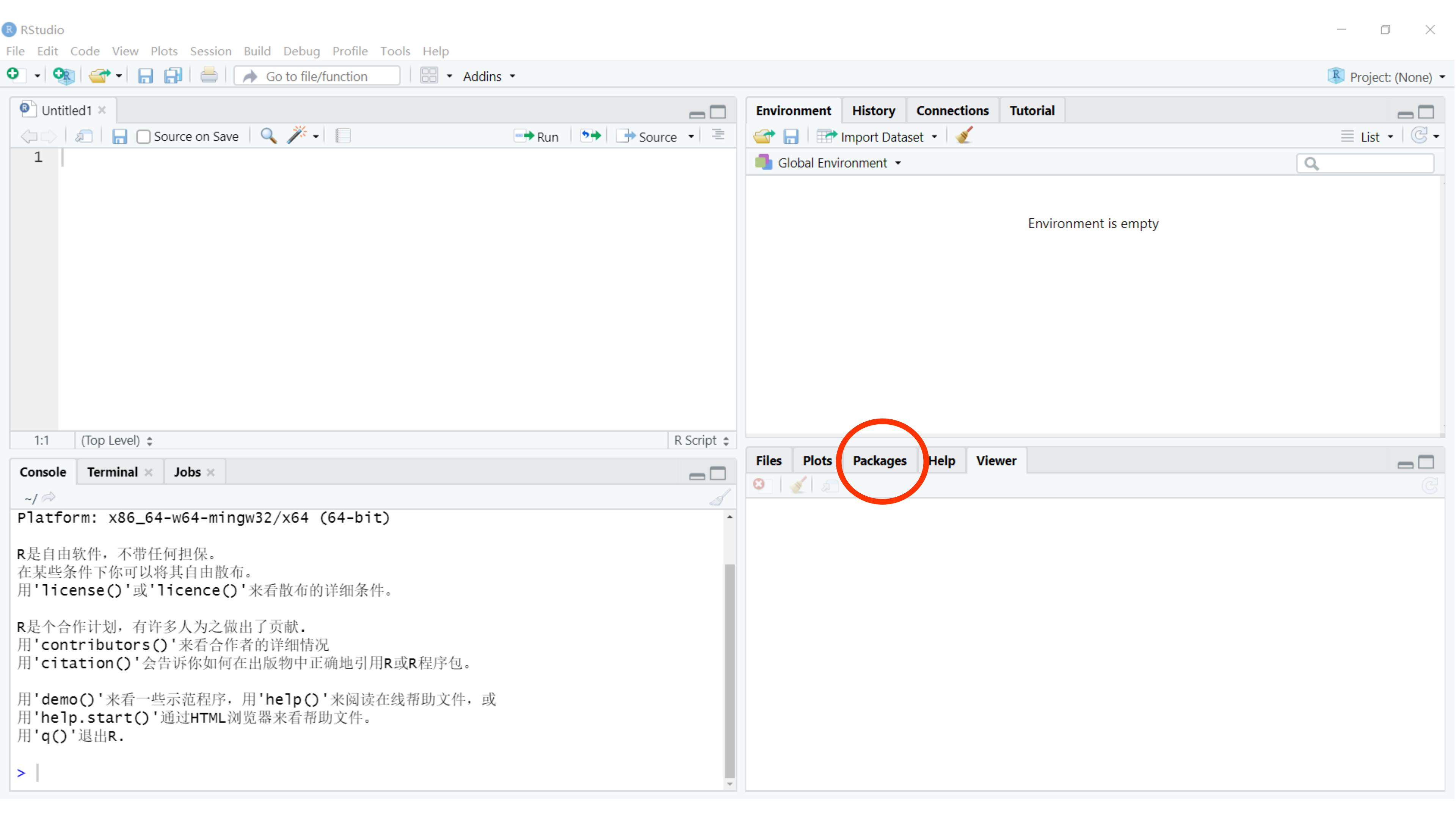
Clicking on this tab will display all of the installed packages with a checkbox next to them. If the box next to a package name is checked, the package is loaded, and if it is empty, the package is not loaded. Click an empty box to load that package and click a checked box to detach that package.
Packages can be installed and updated from the Package tab with the Install and Update buttons at the top of the tab.
Working directory
If you want to read files from a specific location or write files to
a specific location, you need to set working directory in
R. This can be accomplished by specifying path with
setwd() function. First, let’s check the working directory
using getwd().
You can change the working directory using setwd():
Or you may use RStudio through GUI - click Session then
Set Working Directory, followed by
Choose Directory.
Seeking Help
Reading Help files
R, and every package, provides help files for functions.
The general syntax to search for help on any function,
? function_name, from a specific function that is in a
package loaded into your namespace (your interactive R
session):
?function_name or help(function_name)
This will load up a help page in RStudio.
Special Operators
To seek help on special operators, use quotes:
?">="
When you have no idea where to begin
If you don’t know what function or package you need to use CRAN Task Views is a specially maintained list of packages grouped into fields. This can be a good starting point.
When your code doesn’t work: seeking help from your peers
If you are having trouble using a function, 9 times out of 10, the
answers you are seeking have already been
answered on Stack
Overflow. You can search using the [r] tag.
In-class exercises
Exercise #1
- Creat a folder named
ese335- Windows: In
C:\orD:\disk - macOS: In
/home/
- Windows: In
- Change RStudio
Working directoryto the above folder
Exercise #2
What will be the value of each variable after each statement in the program?
- Now type the above codes in Console, check your
results.
- Write a command to compare
X3toX4. Which one is larger? - Clean up your working environment by deleting the
X1,X2, andX3variables.